最近社区都在说 Muon 用在 LLM 上的训练效果要比 AdamW 好很多,这里根据 Kimi 的论文(http://arxiv.org/abs/2502.16982)和仓库做了一些尝试。
选用模型:minimind,Github 链接:https://github.com/jingyaogong/minimind
硬件:AutoDL自己租个 nv 的卡就行
常见的 AdamW 优化器就是在 Adam 的基础上在梯度更新时加上梯度衰减,这样的话可以避免更新的时候产生更大的参数。
而 Muon 并没有走 Adam 的那条路,而是在 Momentum 动量的基础上进行改进,将二维的参数使用 Newton-Schulz iteration 进行更新,其余的部分仍然用 AdamW。
再多了就是一堆社区做过的论文工作了,所以这里放上仓库改好的代码:
import math
import torch
import torch.optim
def _newtonschulz5(x, steps):
"""5th-order Newton-Schulz orthogonalization for 2D matrices.
From Moonlight / KellerJordan: returns US'V^T (not exact UV^T) where
S'_{ii} ~ Uniform(0.5, 1.5). This approximation does not hurt
performance and is cheaper to compute.
"""
assert x.ndim == 2
a, b, c = (3.4445, -4.7750, 2.0315)
X = x.bfloat16()
transposed = X.size(0) > X.size(1)
if transposed:
X = X.T
X = X / (X.norm() + 1e-7)
for _ in range(steps):
A = X @ X.T
B = b * A + c * A @ A
X = a * X + B @ X
if transposed:
X = X.T
return X.float()
_zeropower_fn = _newtonschulz5
if torch.cuda.is_available():
try:
_compiled = torch.compile(_newtonschulz5, fullgraph=True)
_compiled(torch.randn(4, 4, device="cuda"), 1)
_zeropower_fn = _compiled
except Exception:
pass
def zeropower_via_newtonschulz5(G, steps):
return _zeropower_fn(G, steps)
def _adjust_lr_for_muon(lr, param_shape):
"""Scale learning rate by sqrt of the larger matrix dimension.
From the Moonlight paper: adjusted_lr = lr * 0.2 * sqrt(max(rows, cols)).
"""
return lr * 0.2 * math.sqrt(max(param_shape[:2]))
class Muon(torch.optim.Optimizer):
"""Muon — MomentUm Orthogonalized by Newton-Schulz.
2D weight matrices receive an orthogonalized momentum update; all other
parameters (biases, norms, embeddings, lm_head) fall back to AdamW.
Reference: https://github.com/MoonshotAI/Moonlight
"""
def __init__(
self,
params,
lr=1e-3,
weight_decay=0.1,
momentum=0.95,
nesterov=True,
ns_steps=5,
adamw_betas=(0.9, 0.95),
adamw_eps=1e-8,
):
defaults = dict(
lr=lr,
weight_decay=weight_decay,
momentum=momentum,
nesterov=nesterov,
ns_steps=ns_steps,
adamw_betas=adamw_betas,
adamw_eps=adamw_eps,
)
super().__init__(params, defaults)
self._muon_param_ids = set()
self._adamw_param_ids = set()
def mark_muon_params(self, muon_params):
for p in muon_params:
self._muon_param_ids.add(id(p))
self.state[p]["use_muon"] = True
def mark_adamw_params(self, adamw_params):
for p in adamw_params:
self._adamw_param_ids.add(id(p))
self.state[p]["use_muon"] = False
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
lr = group["lr"]
wd = group["weight_decay"]
momentum = group["momentum"]
nesterov = group["nesterov"]
ns_steps = group["ns_steps"]
betas = group["adamw_betas"]
eps = group["adamw_eps"]
muon_params = []
adamw_params = []
for p in group["params"]:
if p.grad is None:
continue
if self.state[p].get("use_muon", False):
muon_params.append(p)
else:
adamw_params.append(p)
# --- Muon update ---
for p in muon_params:
g = p.grad
if g.ndim > 2:
g = g.view(g.size(0), -1)
state = self.state[p]
if "momentum_buffer" not in state:
state["momentum_buffer"] = torch.zeros_like(g)
buf = state["momentum_buffer"]
buf.mul_(momentum).add_(g)
g = g.add(buf, alpha=momentum) if nesterov else buf
u = zeropower_via_newtonschulz5(g, ns_steps)
adjusted_lr = _adjust_lr_for_muon(lr, p.shape)
p.mul_(1 - lr * wd)
p.add_(u.to(dtype=p.dtype), alpha=-adjusted_lr)
# --- AdamW update ---
for p in adamw_params:
g = p.grad
state = self.state[p]
if "step" not in state:
state["step"] = 0
state["exp_avg"] = torch.zeros_like(p)
state["exp_avg_sq"] = torch.zeros_like(p)
state["step"] += 1
step = state["step"]
exp_avg = state["exp_avg"]
exp_avg_sq = state["exp_avg_sq"]
bias1 = 1 - betas[0] ** step
bias2 = 1 - betas[1] ** step
exp_avg.lerp_(g, 1 - betas[0])
exp_avg_sq.lerp_(g.square(), 1 - betas[1])
denom = exp_avg_sq.sqrt().div_(math.sqrt(bias2)).add_(eps)
step_size = lr / bias1
p.addcdiv_(exp_avg, denom, value=-step_size)
if wd != 0:
p.mul_(1 - lr * wd)
return loss
def build_optimizer(model, args):
wd = getattr(args, "weight_decay", 0.1)
if args.optimizer == "adamw":
return torch.optim.AdamW(
model.parameters(), lr=args.learning_rate, weight_decay=wd
)
if args.optimizer != "muon":
raise ValueError(f"Unknown optimizer: {args.optimizer}")
muon_params = []
adamw_params = []
for name, param in model.named_parameters():
if param.ndim >= 2 and "embed_tokens" not in name and "lm_head" not in name:
muon_params.append(param)
else:
adamw_params.append(param)
all_params = muon_params + adamw_params
opt = Muon(
all_params,
lr=args.learning_rate,
weight_decay=wd,
momentum=getattr(args, "muon_momentum", 0.95),
nesterov=True,
ns_steps=getattr(args, "muon_ns_steps", 5),
)
opt.mark_muon_params(muon_params)
opt.mark_adamw_params(adamw_params)
return opt从代码中也能明显看出来,用 AdamW 的时候每次参数更新需要保存两个状态,而用 Muon 只需要保存一个就可以,能节省不少的显存占用。
这里放一下 AdamW 和 Muon 在 500 个 step 迭代之后的 Loss:
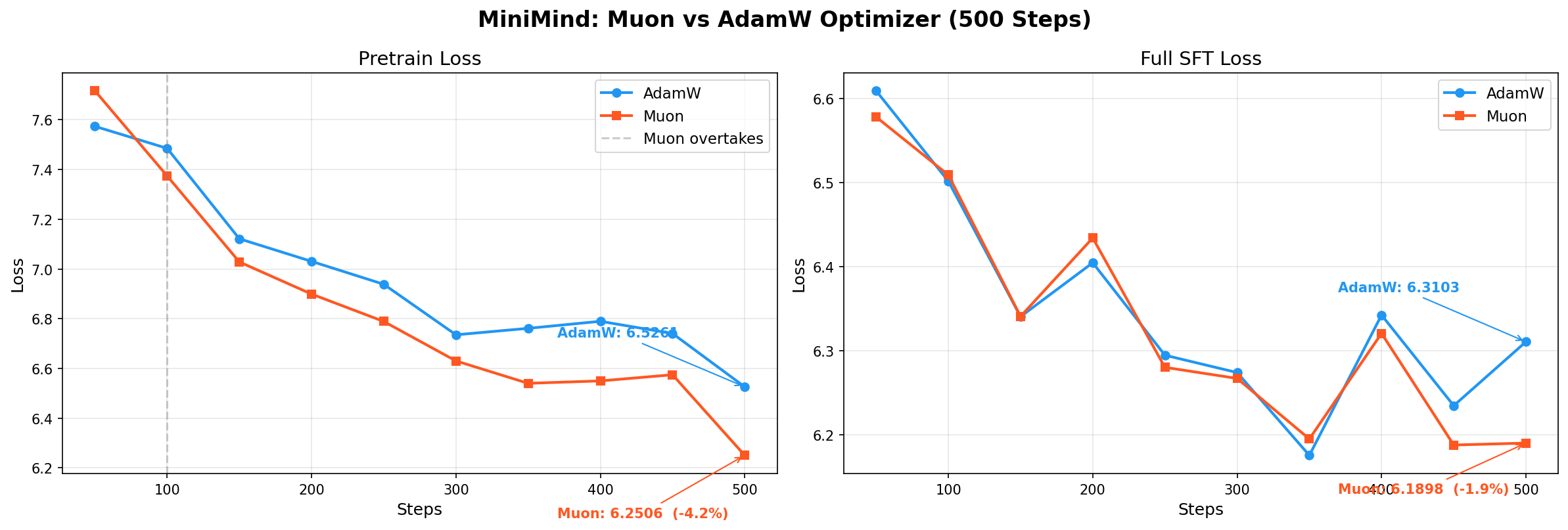
在 Pretrain 阶段时训练速度要比 AdamW 慢一点,但是到 SFT 阶段时可以根据情况做一个早停,这样的话训练速度会快一些。

文章评论