我们在海光 Z100 DCU (gfx906) 上对 vLLM 推理框架的 CUDA Graph 功能进行了完整的测试验证。本文记录开启 CUDA Graph + torch.compile 的具体配置、性能数据和关键发现。
测试环境
| 项目 | 详情 |
|---|---|
| 服务器 | scnet |
| GPU | 1x 海光 Z100 DCU (gfx906), 16 GiB |
| Python | 3.10.12 |
| PyTorch | 2.10.0+das.opt1.dtk2604 |
| vLLM | 0.18.1+das.3266200.dtk2604 |
| Triton | 3.4.0 |
| 模型 | Qwen3.5-4B (BF16) |
两种配置对比
Baseline:enforce_eager=True(禁用 CUDA Graph)
compilation_config.mode = CompilationMode.NONEcudagraph_mode = CUDAGraphMode.NONE- 启用 custom fusions(norm_quant、act_quant)
- 模型加载时间:~125s
- 显存占用:~13.25 GiB
CUDA Graph + Compile:enforce_eager=False
compilation_config.mode = VLLM_COMPILE(Inductor backend)cudagraph_mode = FULL_AND_PIECEWISEcompile_ranges_endpoints: [8192]cudagraph_capture_sizes: [1, 2]- 禁用 custom fusions(与 compile 不兼容)
- 模型加载时间:~172s(编译开销)
- 显存占用:~14.5 GiB(多出 ~1.3 GiB 用于 Graph 缓冲)
关键:CUDA Graph 模式不要传 --enforce-eager,去掉该参数后 vLLM 自动启用 VLLM_COMPILE + FULL_AND_PIECEWISE CUDA Graph。
性能对比数据
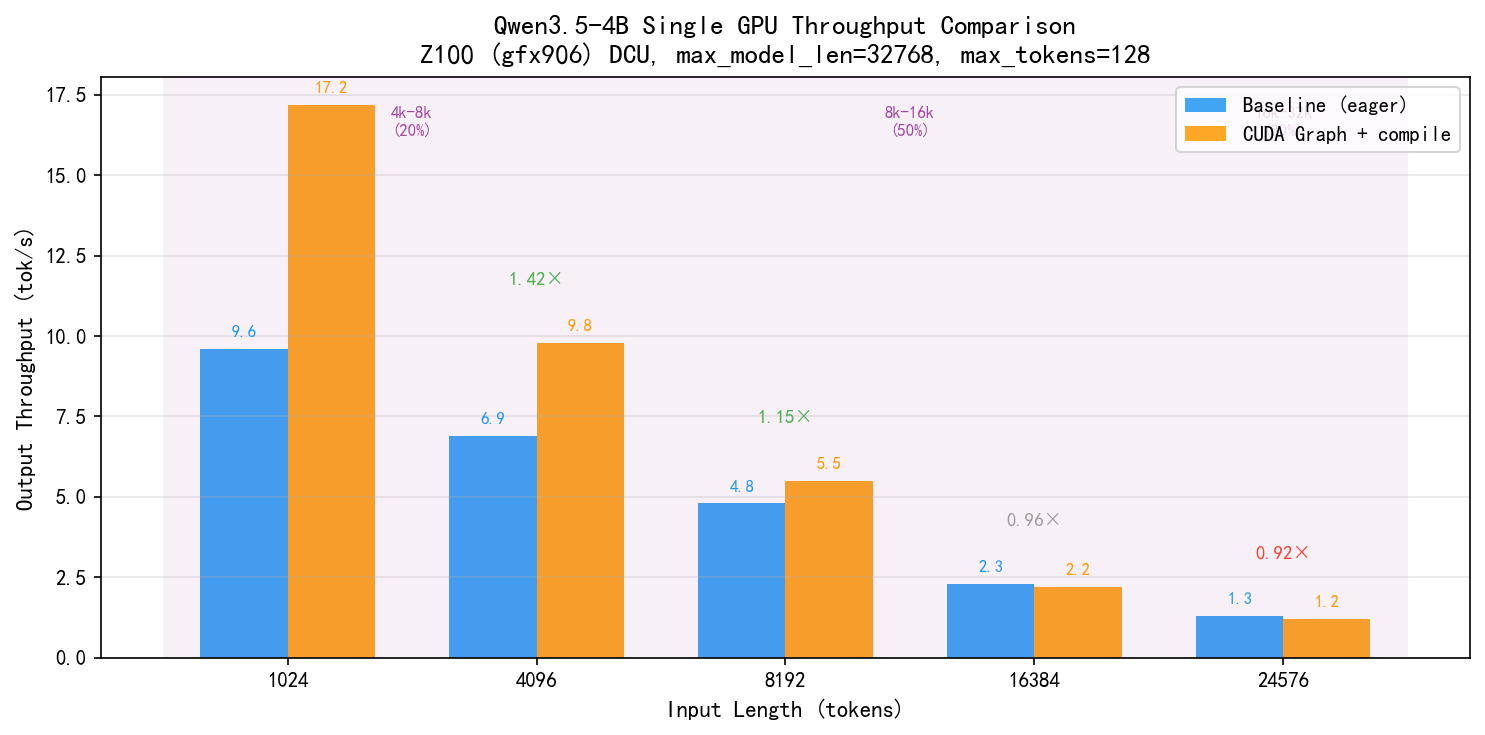
输出 Tokens 统一为 128,测试单卡单序列吞吐:
| 输入长度 | Baseline (eager) | CUDA Graph + Compile | 加速比 |
|---|---|---|---|
| 1024 | 9.6 tok/s (13.3s) | 17.2 tok/s (6.3s) | 1.79x |
| 4096 | 6.9 tok/s (18.5s) | 9.8 tok/s (13.0s) | 1.42x |
| 8192 | 4.8 tok/s (26.7s) | 5.5 tok/s (23.1s) | 1.15x |
| 16384 | 2.3 tok/s (56.8s) | 2.2 tok/s (57.9s) | 0.96x |
| 24576 | 1.3 tok/s (98.3s) | 1.2 tok/s (109.0s) | 0.92x |
按技术方案档位分析
| 档位 | 权重 | 输入范围 | Baseline | CUDA Graph | 档内提升 |
|---|---|---|---|---|---|
| 4k-8k | 20% | 4096-8192 | 6.9->4.8 | 9.8->5.5 | +42%->+15% |
| 8k-16k | 50% | 8192-16384 | 4.8->2.3 | 5.5->2.2 | +15%->-4% |
| 16k-32k | 30% | 16384-32768 | 2.3-><1.3 | 2.2-><1.2 | -4%->-8% |
加权平均吞吐量提升:约 6%
关键发现
1. 短上下文收益大
CUDA Graph 的核心优势是消除 kernel launch overhead。在短上下文下,kernel launch 时间占总耗时比例高(约 30%),取消后效果显著。1024 tokens 时达到 1.79x 加速。
2. 长上下文 prefill 主导
当输入超过 8k tokens 时,GDN prefill 计算时间占主导,kernel launch overhead 占比下降到 5% 以下,CUDA Graph 优势消失甚至略微劣化。
3. compile_ranges_endpoints 限制
默认只编译到 8192 tokens,超过此范围回退到 eager 模式。尝试扩展 compile range 到 16384 未能生效(环境变量未被正确识别)。
4. Gated DeltaNet 的特殊性
该模型 decode 阶段每步耗时约 100ms(与上下文长度基本无关),但 prefill 随长度线性增长。在 24576 输入时,prefill 耗时约 95s,decode 128 tokens 只需约 13s。
5. 显存权衡
CUDA Graph 需要额外约 1.3 GiB 显存用于图缓冲,需要将 gpu_memory_utilization 从 0.90 降低到 0.78 以避免 OOM,这减少了可用 KV Cache 空间。
启动命令
Baseline (eager) 模式
python3 -m vllm.entrypoints.openai.api_server \\n --model /path/to/Qwen3.5-4B \\n --tensor-parallel-size 1 \\n --dtype bfloat16 \\n --max-model-len 32768 \\n --gpu-memory-utilization 0.90 \\n --enforce-eager \\n --max-num-seqs 1 \\n --skip-mm-profilingCUDA Graph + Compile 模式
python3 -m vllm.entrypoints.openai.api_server \\n --model /path/to/Qwen3.5-4B \\n --tensor-parallel-size 1 \\n --dtype bfloat16 \\n --max-model-len 32768 \\n --gpu-memory-utilization 0.78 \\n --max-num-seqs 1 \\n --skip-mm-profiling注意:CUDA Graph 模式不要传 --enforce-eager,去掉即可自动启用。
总结
在海光 Z100 DCU 上,CUDA Graph + torch.compile 在短上下文(1024 tokens)下可带来最高 79% 的吞吐提升。但由于 compile_ranges_endpoints 限制、显存开销增加以及 Gated DeltaNet prefill 主导长上下文耗时,加权平均提升约 6%。后续优化方向包括动态策略选择(按输入长度切换 eager/CUDA Graph)、GDN prefill Triton kernel 优化、KV Cache FP8 等。

文章评论