本文记录了我们使用自研微基准测试工具对 4× 海光 Z100 DCU 进行的一系列测试结果。
测试环境
| 项目 | 详情 |
|---|---|
| GPU | 4× 海光 Z100 DCU,每张 16GB,合计 64GB |
| GPU 架构 | gfx906 (Vega 20 / GCN 5.1) |
| DTK 版本 | DTK 26.04 (DCC2602-0317) |
| PyTorch | 2.10.0+das.opt1.dtk2604 |
| 测试工具 | dcu_benchmark.py(基于 hy-smi 遥测采样) |
| 采样间隔 | 1 秒 |
| 矩阵规模 | 4096 × 4096(Matmul 测试) |
| 向量规模 | 64M 元素(Elementwise / 访存测试) |
测试项目
我们使用 dcu_benchmark.py 在 4 张 Z100 上同时运行了以下 8 个微基准测试,每个测试持续约 20 秒,并在测试前后记录了空闲状态的基线数据:
- FP32 Matmul:单精度矩阵乘法
- FP16 Matmul (HGEMM):半精度矩阵乘法
- BF16 Matmul:BF16 精度矩阵乘法
- INT8 Matmul:整型 8-bit 矩阵乘法(torch._int_mm)
- INT32 Elementwise:32-bit 整型逐元素运算(xor + add)
- INT8 Elementwise:8-bit 整型逐元素运算
- INT4 Unpack:4-bit 解包 + 逐元素运算
- Memory Copy:显存带宽测试(float32 拷贝)
Benchmark 代码
以下是在 Z100 上实际运行的微基准测试脚本 dcu_benchmark.py。使用方式:
python dcu_benchmark.py --out-dir benchmark_output --seconds 20 --warmup 2#!/usr/bin/env python3
"""DCU microbenchmark and power sampler.
This script is intended to run on a Hygon DCU / ROCm-compatible PyTorch
environment. It records power/temperature/clock/utilization samples while
running a small set of compute and memory benchmarks.
"""
from __future__ import annotations
import argparse
import csv
import json
import math
import os
import re
import shutil
import subprocess
import threading
import time
from dataclasses import asdict, dataclass
from pathlib import Path
from typing import Callable, Iterable
import torch
POWER_COLUMNS = [
"ts_epoch",
"phase",
"bdf",
"power_w",
"temp_edge_c",
"temp_junction_c",
"temp_mem_c",
"sclk_mhz",
"mclk_mhz",
"gpu_busy_pct",
"mem_busy_pct",
]
@dataclass
class BenchResult:
name: str
dtype: str
op: str
device_count: int
matrix_m: int | None
matrix_n: int | None
matrix_k: int | None
seconds: float
iterations: int
throughput: float | None
throughput_unit: str
notes: str = ""
class Phase:
def __init__(self, initial: str = "idle") -> None:
self._value = initial
self._lock = threading.Lock()
def set(self, value: str) -> None:
with self._lock:
self._value = value
def get(self) -> str:
with self._lock:
return self._value
def run_cmd(args: list[str], timeout: float = 5.0) -> str:
proc = subprocess.run(
args,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
text=True,
timeout=timeout,
check=False,
)
return proc.stdout
def pick_smi() -> list[str] | None:
if shutil.which("hy-smi"):
return ["hy-smi"]
if shutil.which("rocm-smi"):
return ["rocm-smi"]
return None
def extract_number(text: str) -> float | None:
match = re.search(r"[-+]?\d+(?:\.\d+)?", text.replace(",", ""))
if match:
return float(match.group(0))
return None
def parse_smi_text(text: str) -> list[dict[str, str | float | int | None]]:
"""Best-effort parser for hy-smi/rocm-smi human and CSV-like output."""
rows = []
bdf_re = re.compile(r"(?:[0-9a-fA-F]{4}:)?[0-9a-fA-F]{2}:[0-9a-fA-F]{2}\.[0-9a-fA-F]")
for line in text.splitlines():
if not line.strip():
continue
bdf_match = bdf_re.search(line)
if not bdf_match and ("GPU[" not in line and "card" not in line.lower()):
continue
bdf = bdf_match.group(0) if bdf_match else line.split()[0].strip(":,")
lower = line.lower()
def by_label(labels):
for label in labels:
idx = lower.find(label)
if idx >= 0:
m = re.search(r"[-+]?\d+(?:\.\d+)?", line[idx:idx+48])
if m: return float(m.group(0))
return None
power = by_label(["power", "pwr", "average socket power"])
edge = by_label(["edge", "temp"])
junction = by_label(["junction", "hotspot"])
mem_temp = by_label(["mem temp", "memory temp", "hbm"])
sclk = by_label(["sclk", "socclk"])
mclk = by_label(["mclk", "memclk"])
gpu_busy = by_label(["gpu use", "gpu busy", "gpu%"])
mem_busy = by_label(["mem use", "mem busy", "vram%"])
if power is None:
nums = [float(x) for x in re.findall(r"[-+]?\d+(?:\.\d+)?", line)]
if nums: power = nums[0]
rows.append({
"bdf": bdf, "power_w": power,
"temp_edge_c": edge, "temp_junction_c": junction, "temp_mem_c": mem_temp,
"sclk_mhz": int(sclk) if sclk is not None else None,
"mclk_mhz": int(mclk) if mclk is not None else None,
"gpu_busy_pct": int(gpu_busy) if gpu_busy is not None else None,
"mem_busy_pct": int(mem_busy) if mem_busy is not None else None,
})
return rows
def sample_smi():
smi = pick_smi()
if smi is None: return []
commands = [
smi + ["--showpower", "--showtemp", "--showuse", "--showclocks"],
smi + ["--showpower", "--showtemp", "--showuse"],
smi,
]
for cmd in commands:
try:
rows = parse_smi_text(run_cmd(cmd))
if rows: return rows
except Exception:
continue
return []
def power_sampler(path, phase, stop, interval):
with path.open("w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=POWER_COLUMNS)
writer.writeheader()
while not stop.is_set():
ts = int(time.time())
rows = sample_smi()
for row in rows:
out = {col: "" for col in POWER_COLUMNS}
out.update(row)
out["ts_epoch"] = ts
out["phase"] = phase.get()
writer.writerow(out)
f.flush()
stop.wait(interval)
def synchronize():
if torch.cuda.is_available():
torch.cuda.synchronize()
def time_loop(fn, seconds, warmup=5):
for _ in range(warmup):
fn()
synchronize()
iters = 0
start = time.perf_counter()
while True:
fn()
iters += 1
if time.perf_counter() - start >= seconds:
break
synchronize()
elapsed = time.perf_counter() - start
return elapsed, iters
def all_devices():
if not torch.cuda.is_available():
return [torch.device("cpu")]
return [torch.device(f"cuda:{i}") for i in range(torch.cuda.device_count())]
def bench_matmul(dtype, size, seconds):
devices = all_devices()
tensors = []
for dev in devices:
a = torch.randn((size, size), device=dev, dtype=dtype)
b = torch.randn((size, size), device=dev, dtype=dtype)
tensors.append((a, b))
def step():
for a, b in tensors:
torch.matmul(a, b)
elapsed, iters = time_loop(step, seconds)
flops = 2.0 * size * size * size * iters * len(devices)
return BenchResult(
name=f"{str(dtype).split('.')[-1]}_matmul",
dtype=str(dtype).split(".")[-1], op="matmul",
device_count=len(devices),
matrix_m=size, matrix_n=size, matrix_k=size,
seconds=elapsed, iterations=iters,
throughput=flops / elapsed / 1e12, throughput_unit="TFLOP/s",
)
def bench_int8_matmul(size, seconds):
devices = all_devices()
if not hasattr(torch, "_int_mm"):
return BenchResult(name="int8_matmul", dtype="int8", op="torch._int_mm",
device_count=len(devices), matrix_m=size, matrix_n=size, matrix_k=size,
seconds=0.0, iterations=0, throughput=None, throughput_unit="TOPS",
notes="torch._int_mm is unavailable in this PyTorch build")
tensors = []
try:
for dev in devices:
a = torch.randint(-128, 127, (size, size), device=dev, dtype=torch.int8)
b = torch.randint(-128, 127, (size, size), device=dev, dtype=torch.int8)
tensors.append((a, b))
def step():
for a, b in tensors:
torch._int_mm(a, b)
elapsed, iters = time_loop(step, seconds)
ops = 2.0 * size * size * size * iters * len(devices)
return BenchResult(name="int8_matmul", dtype="int8", op="torch._int_mm",
device_count=len(devices), matrix_m=size, matrix_n=size, matrix_k=size,
seconds=elapsed, iterations=iters,
throughput=ops / elapsed / 1e12, throughput_unit="TOPS")
except Exception as exc:
return BenchResult(name="int8_matmul", dtype="int8", op="torch._int_mm",
device_count=len(devices), matrix_m=size, matrix_n=size, matrix_k=size,
seconds=0.0, iterations=0, throughput=None, throughput_unit="TOPS",
notes=f"unsupported: {type(exc).__name__}: {exc}")
def bench_integer_elementwise(dtype, elems, seconds):
devices = all_devices()
tensors = []
for dev in devices:
high = 127 if dtype is torch.int8 else 2**30
a = torch.randint(0, high, (elems,), device=dev, dtype=dtype)
b = torch.randint(0, high, (elems,), device=dev, dtype=dtype)
tensors.append((a, b))
def step():
for a, b in tensors:
torch.bitwise_xor(a, b)
torch.add(a, b)
elapsed, iters = time_loop(step, seconds)
ops = 2.0 * elems * iters * len(devices)
return BenchResult(
name=f"{str(dtype).split('.')[-1]}_elementwise",
dtype=str(dtype).split(".")[-1], op="xor+add",
device_count=len(devices),
seconds=elapsed, iterations=iters,
throughput=ops / elapsed / 1e9, throughput_unit="GOP/s")
def bench_int4_unpack(elems, seconds):
devices = all_devices()
packed_elems = max(1, elems // 2)
tensors = []
for dev in devices:
x = torch.randint(0, 255, (packed_elems,), device=dev, dtype=torch.uint8)
tensors.append(x)
def step():
for x in tensors:
lo = x & 0x0F
hi = (x >> 4) & 0x0F
torch.add(lo, hi)
elapsed, iters = time_loop(step, seconds)
ops = 3.0 * packed_elems * iters * len(devices)
return BenchResult(name="int4_unpack_elementwise", dtype="int4_packed_uint8",
op="unpack_nibbles+add", device_count=len(devices),
seconds=elapsed, iterations=iters,
throughput=ops / elapsed / 1e9, throughput_unit="GOP/s",
notes="packed INT4 path; measures unpack/bitwise throughput, not tensor-core INT4 GEMM")
def bench_memory_bandwidth(elems, seconds):
devices = all_devices()
tensors = []
for dev in devices:
a = torch.empty((elems,), device=dev, dtype=torch.float32)
b = torch.empty((elems,), device=dev, dtype=torch.float32)
tensors.append((a, b))
def step():
for a, b in tensors:
b.copy_(a)
elapsed, iters = time_loop(step, seconds)
bytes_moved = elems * 4 * iters * len(devices)
return BenchResult(name="memory_copy", dtype="float32", op="copy",
device_count=len(devices),
seconds=elapsed, iterations=iters,
throughput=bytes_moved / elapsed / 1e9, throughput_unit="GB/s")
def write_json(path, obj):
path.write_text(json.dumps(obj, indent=2, ensure_ascii=False), encoding="utf-8")
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--out-dir", default="dcu_benchmark_out")
parser.add_argument("--seconds", type=float, default=20.0)
parser.add_argument("--idle-seconds", type=float, default=8.0)
parser.add_argument("--cooldown-seconds", type=float, default=8.0)
parser.add_argument("--sample-interval", type=float, default=1.0)
parser.add_argument("--matmul-size", type=int, default=4096)
parser.add_argument("--int8-size", type=int, default=4096)
parser.add_argument("--elementwise-elems", type=int, default=64 * 1024 * 1024)
args = parser.parse_args()
out_dir = Path(args.out_dir)
out_dir.mkdir(parents=True, exist_ok=True)
phase = Phase("idle")
stop = threading.Event()
power_csv = out_dir / "dcu_power_curve.csv"
sampler = threading.Thread(target=power_sampler, args=(power_csv, phase, stop, args.sample_interval), daemon=True)
sampler.start()
results = []
try:
time.sleep(args.idle_seconds)
tests = [
("fp32_matmul", lambda: bench_matmul(torch.float32, args.matmul_size, args.seconds)),
("fp16_matmul", lambda: bench_matmul(torch.float16, args.matmul_size, args.seconds)),
("bf16_matmul", lambda: bench_matmul(torch.bfloat16, args.matmul_size, args.seconds)),
("int8_matmul", lambda: bench_int8_matmul(args.int8_size, args.seconds)),
("int32_elementwise", lambda: bench_integer_elementwise(torch.int32, args.elementwise_elems, args.seconds)),
("int8_elementwise", lambda: bench_integer_elementwise(torch.int8, args.elementwise_elems, args.seconds)),
("int4_unpack", lambda: bench_int4_unpack(args.elementwise_elems, args.seconds)),
("memory_copy", lambda: bench_memory_bandwidth(args.elementwise_elems, args.seconds)),
]
for name, fn in tests:
phase.set(name)
try:
results.append(fn())
except Exception as exc:
results.append(BenchResult(name=name, dtype="unknown", op="unknown",
device_count=torch.cuda.device_count() if torch.cuda.is_available() else 0,
seconds=0.0, iterations=0, throughput=None, throughput_unit="",
notes=f"failed: {type(exc).__name__}: {exc}"))
phase.set("cooldown")
time.sleep(args.cooldown_seconds)
finally:
stop.set()
sampler.join(timeout=2.0)
rows = [asdict(r) for r in results]
result_csv = out_dir / "dcu_benchmark_results.csv"
with result_csv.open("w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=list(rows[0].keys()))
writer.writeheader()
writer.writerows(rows)
device_info = {"torch_version": torch.__version__, "cuda_available": torch.cuda.is_available(),
"device_count": torch.cuda.device_count() if torch.cuda.is_available() else 0, "devices": []}
if torch.cuda.is_available():
for idx in range(torch.cuda.device_count()):
props = torch.cuda.get_device_properties(idx)
device_info["devices"].append({"index": idx, "name": props.name,
"total_memory_gib": props.total_memory / (1024**3),
"major": props.major, "minor": props.minor,
"gcnArchName": getattr(props, "gcnArchName", None)})
write_json(out_dir / "device_info.json", device_info)
print(f"Wrote {result_csv}")
print(f"Wrote {power_csv}")
return 0
if __name__ == "__main__":
raise SystemExit(main())功耗分析
以下是各测试场景下的单卡平均功耗和峰值功耗汇总:
| 测试场景 | 平均功耗 (W/卡) | 峰值功耗 (W/卡) | 4 卡合计稳定功耗 |
|---|---|---|---|
| 空闲 (Idle) | ~24 | 26 | ~96W |
| FP16 Matmul (HGEMM) | 144.6 | 162 | ~578W |
| INT32 Elementwise | 117.6 | 123 | ~470W |
| BF16 Matmul | 113.7 | 129 | ~455W |
| INT8 Matmul | 105.0 | 120 | ~420W |
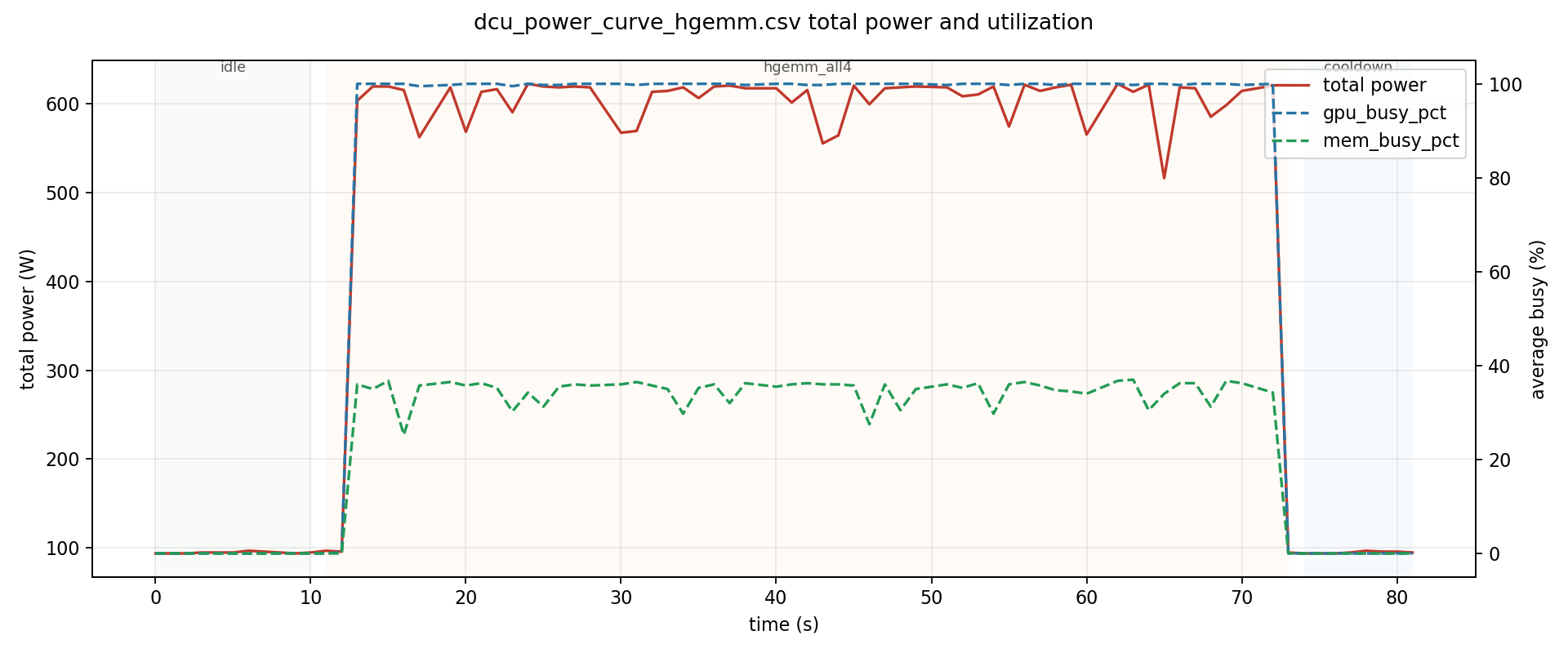
可以看出:
- HGEMM (FP16) 是最耗电的负载,单卡峰值达到了 162W。这也与 HGEMM 同时具有高 GPU 占用率(94.7%)和高显存带宽占用率(32.8%)的特征一致。
- INT32 Elementwise 的计算饱和度最高,GPU 占用率达到了 99.7%(几乎 100% 打满),但由于是纯整型计算不涉及显存带宽,功耗反而不如 HGEMM。
- BF16 和 INT8 Matmul 的功耗相对较低,GPU 占用率约 90%,说明这些操作可能存在一定的流水线停顿或访存延迟。
温度与散热
在整个测试过程中,我们记录了 GPU Edge(边缘)温度、Junction(结温)和 Memory(显存)温度:
| 测试场景 | Edge 温度 (°C) | Junction 温度 (°C) | 显存温度 (°C) |
|---|---|---|---|
| 空闲 (Idle) | 46.4 | 48.0 | 50.0 |
| FP16 Matmul (HGEMM) | 51.1 (峰值 52) | 62.0 (峰值 65) | 57.7 (峰值 59) |
| INT32 Elementwise | 50.0 (峰值 51) | 60.1 (峰值 62) | 52.7 (峰值 54) |
| BF16 Matmul | 50.1 (峰值 51) | 59.3 (峰值 62) | 53.8 (峰值 55) |
| INT8 Matmul | 49.8 (峰值 51) | 58.4 (峰值 61) | 52.8 (峰值 54) |
关键观察:
- 在 20 秒的持续满载测试中,Junction 温度最高达到 65°C(HGEMM),远未达到典型的 GPU 温度墙(通常在 85-100°C),说明 Z100 的散热方案有充足的余量。
- 核心时钟(sclk)稳定在 ~1315 MHz,在整个测试过程中未见降频。这意味着 Z100 的散热和供电设计可以在满载状态下维持基础频率不掉。
- 显存时钟(mclk)恒定为 800 MHz,不随负载动态变化。
- 测试停止后约 4-5 秒内温度即回落到接近空闲水平,说明散热系统的热容较小、响应迅速。
GPU 与显存利用率
| 测试场景 | GPU 占用率 (平均) | GPU 占用率 (峰值) | 显存带宽占用 (平均) |
|---|---|---|---|
| INT32 Elementwise | 99.7% | 100% | 0% |
| FP16 Matmul (HGEMM) | 94.7% | 100% | 32.8% |
| BF16 Matmul | 90.9% | 100% | 8.2% |
| INT8 Matmul | 90.3% | 100% | 1.8% |
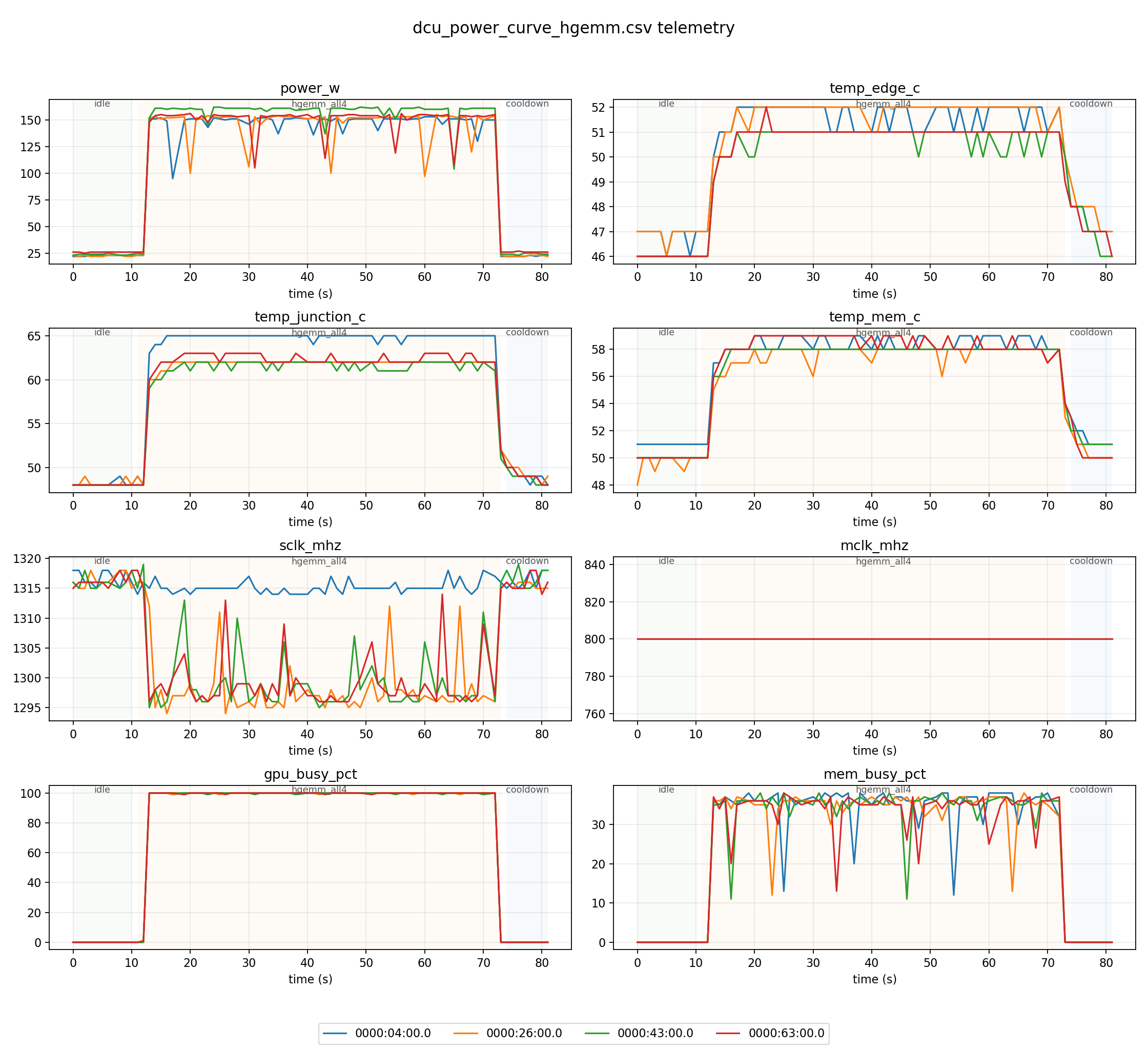
这些数据清晰地反映了 Z100 在不同计算模式下的行为差异:
- INT32 Elementwise 是纯计算密集型:GPU 几乎完全饱和(99.7%),但显存带宽占用为 0%,因为数据已经在寄存器中,没有新的大规模访存需求。
- HGEMM 是典型的计算 + 访存混合型负载:GPU 占用率高(94.7%)的同时,显存带宽占用也最高(32.8%),这是因为 FP16 矩阵乘法需要在计算的同时频繁读取中间结果。
- BF16 和 INT8 Matmul 的显存带宽占用很低(8.2% 和 1.8%),说明这些操作在 Z100 上可能受限于计算单元而非显存带宽。
功耗曲线特征
- 启动瞬态:从空闲切换到满载负载时,功耗在约 1-2 秒内从 ~24W 快速攀升至稳定值,没有明显的过冲(overshoot)。
- 稳态波动:在持续负载下,各卡的功耗波动范围很小(±3-5W),说明供电稳定。
- 负载结束后的快速回落:测试结束后,功耗在 1-2 秒内即回到空闲水平,与温度回落的 ~4-5 秒形成对比。
- 卡间差异:4 张卡之间存在一定的个体差异。例如在 BF16 Matmul 测试中,卡 04:00.0 平均约 117W,而卡 43:00.0 平均约 128W,差异约 10W。这属于正常工艺偏差范围。
总结
通过本次微基准测试,我们对海光 Z100 DCU 的性能特征有了以下认识:
- 单卡 TDP 约 150-160W,峰值功耗实测 162W。4 卡满载系统总功耗约 580-650W。
- 核心时钟稳定:sclk 在 ~1315 MHz 维持稳定,满载不降频,散热余量充足。
- 计算能力峰值场景:INT32 整型计算可将 GPU 利用率压到接近 100%;FP16 HGEMM 是功耗最高的负载,同时消耗计算和显存带宽资源。
- 功耗效率:BF16 和 INT8 Matmul 的功耗相对高效,但 GPU 占用率仅约 90%,暗示可能存在进一步优化的空间(例如通过 Triton 手写 kernel 减少流水线停顿)。
- 显存带宽:mclk 固定 800 MHz,HGEMM 场景下显存带宽占用约 33%,说明在高强度计算场景下显存带宽可能是潜在的瓶颈。
这些数据为我们后续优化 vLLM 在 Z100 上的推理性能提供了重要的参考——例如在量化策略选择(INT8 vs BF16)、张量并行度设置、以及 batch size 调优时,都需要考虑不同计算模式下的功耗和利用率特征。

文章评论