记录写kaggle练习时记录的东西
最基础的决策树模型
下面是假设:
你的表弟靠房地产投机赚了数百万美元。他因为你对数据科学感兴趣,所以提出和你合伙做生意。他出资,你则提供预测不同房屋价值的模型。
你问表弟过去是如何预测房产价值的,他说只是凭直觉。但进一步询问后发现,他其实是从过去看过的房子中总结出了价格规律,并利用这些规律来预测他正在考虑的新房的价格。
机器学习的工作原理也类似。我们将从一种叫做决策树的模型开始。虽然还有更高级的模型可以给出更准确的预测,但决策树易于理解,并且是数据科学领域一些最佳模型的基础构建模块。

它将房屋仅分为两类。任何待评估房屋的预测价格都是同类房屋的历史平均价格。
我们利用数据决定如何将房屋分成两组,然后再确定每组的预测价格。从数据中捕捉模式的这一步骤称为模型拟合或训练 。用于拟合模型的数据称为训练数据 。
你可以使用具有更多“分支”的决策树来捕捉更多因素。这些决策树被称为“深层”决策树。例如,一个同时考虑每栋房屋地块总面积的决策树可能如下所示:

预测任何房屋的价格,只需遍历决策树,始终选择与该房屋特征相对应的路径即可。预测的房屋价格位于决策树的底部。我们进行预测的底部点称为叶子节点。
一些Python和库的基本操作
Pandas 库中最重要的部分是 DataFrame。DataFrame 存储的数据类型类似于表格。这类似于 Excel 中的工作表或 SQL 数据库中的表。Pandas 为处理此类数据的大部分需求提供了强大的方法。
例如,我们将查看澳大利亚墨尔本的房价数据 。在实践练习中,您将把相同的流程应用到一个新的数据集,该数据集包含爱荷华州的房价数据。
示例(墨尔本)数据位于文件路径 ../input/melbourne-housing-snapshot/melb_data.csv 。
我们使用以下命令加载和探索数据:
# save filepath to variable for easier access</em>
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# read the data and store data in DataFrame titled melbourne_data</em>
melbourne_data = pd.read_csv(melbourne_file_path)
# print a summary of the data in Melbourne data</em>
melbourne_data.describe()Rooms | Price | Distance | Postcode | Bedroom2 | Bathroom | Car | Landsize | BuildingArea | YearBuilt | Lattitude | Longtitude | Propertycount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 13580.000000 | 1.358000e+04 | 13580.000000 | 13580.000000 | 13580.000000 | 13580.000000 | 13518.000000 | 13580.000000 | 7130.000000 | 8205.000000 | 13580.000000 | 13580.000000 | 13580.000000 |
| mean | 2.937997 | 1.075684e+06 | 10.137776 | 3105.301915 | 2.914728 | 1.534242 | 1.610075 | 558.416127 | 151.967650 | 1964.684217 | -37.809203 | 144.995216 | 7454.417378 |
| std | 0.955748 | 6.393107e+05 | 5.868725 | 90.676964 | 0.965921 | 0.691712 | 0.962634 | 3990.669241 | 541.014538 | 37.273762 | 0.079260 | 0.103916 | 4378.581772 |
| min | 1.000000 | 8.500000e+04 | 0.000000 | 3000.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1196.000000 | -38.182550 | 144.431810 | 249.000000 |
| 25% | 2.000000 | 6.500000e+05 | 6.100000 | 3044.000000 | 2.000000 | 1.000000 | 1.000000 | 177.000000 | 93.000000 | 1940.000000 | -37.856822 | 144.929600 | 4380.000000 |
| 50% | 3.000000 | 9.030000e+05 | 9.200000 | 3084.000000 | 3.000000 | 1.000000 | 2.000000 | 440.000000 | 126.000000 | 1970.000000 | -37.802355 | 145.000100 | 6555.000000 |
| 75% | 3.000000 | 1.330000e+06 | 13.000000 | 3148.000000 | 3.000000 | 2.000000 | 2.000000 | 651.000000 | 174.000000 | 1999.000000 | -37.756400 | 145.058305 | 10331.000000 |
| max | 10.000000 | 9.000000e+06 | 48.100000 | 3977.000000 | 20.000000 | 8.000000 | 10.000000 | 433014.000000 | 44515.000000 | 2018.000000 | -37.408530 | 145.526350 | 21650.000000 |
数据集包含太多变量,你难以理解,甚至无法清晰地打印出来。如何才能将这些海量数据精简成你能理解的形式?我们将首先凭直觉选择几个变量。要选择变量/列,我们需要查看数据集中的所有列。这可以通过 DataFrame 的 columns 属性完成(如下代码的最后一行)。
melbourne_data.columnsIndex(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
你可以使用点号表示法提取变量。这一列存储在 Series 中,它与 DataFrame 非常相似,只是只有一列数据。我们将使用点号表示法来选择要预测的列,这列被称为预测目标 。按照惯例,预测目标被称为 y 。
y = melbourne_data.Price输入到模型中的列(之后用于进行预测)被称为“特征”。在本例中,这些特征就是用于确定房价的列。有时,除了目标值之外的所有列都会被用作特征。而有时,使用较少的特征效果会更好。
现在,我们将构建一个只包含少量特征的模型。稍后您将看到如何迭代并比较使用不同特征构建的模型。
我们通过在方括号内提供列名列表来选择多个特征。列表中的每一项都应该是一个字符串(带引号)。按照惯例,这些数据被称为 X。
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]构建和使用模型的步骤如下:
- 明确定义: 模型类型是什么?决策树?还是其他类型的模型?模型类型的其他一些参数也已指定。
- 拟合: 从提供的数据中捕捉模式。这是建模的核心。
- 对得到的模型进行预测
- 评估 :确定模型预测的准确性。
from sklearn.tree import DecisionTreeRegressor
# Define model. Specify a number for random_state to ensure same results each run
melbourne_model = DecisionTreeRegressor(random_state=1)
# Fit model
melbourne_model.fit(X, y)许多机器学习模型允许在模型训练过程中存在一定的随机性。为 random_state 指定一个数值可以确保每次运行都得到相同的结果。这被认为是一种良好的实践。你可以使用任意数值,模型质量不会显著依赖于你选择的具体值。
模型验证(Only MAE)
几乎你构建的每一个模型都需要进行评估。在大多数(但并非所有)应用中,衡量模型质量的相关指标是预测准确率。换句话说,就是模型的预测结果是否接近实际情况。很多人在衡量预测准确率时会犯一个巨大的错误。他们用训练数据进行预测,然后将这些预测值与训练数据中的目标值进行比较。稍后您就会看到这种方法的弊端以及如何解决它,但我们先来思考一下应该如何操作。
首先,你需要用一种易于理解的方式概括模型的质量。如果你比较1万套房屋的预测房价和实际房价,很可能会发现预测结果好坏参半。逐一查看这1万个预测值和实际值的列表毫无意义。我们需要将其概括为一个单一的指标。有很多指标可以用来概括模型质量,但我们先从一个名为平均绝对误差 (也称 MAE )的指标开始。
使用平均绝对误差 (MAE) 指标时,我们取每个误差的绝对值,将每个误差转换为正数。然后,我们计算这些绝对误差的平均值。这就是我们衡量模型质量的指标。简单来说,可以这样表述:平均而言,我们的预测误差约为 X。
可以通过sklearn库中的自带的函数进行调用
from sklearn.metrics import mean_absolute_error predicted_home_prices = melbourne_model.predict(X) mean_absolute_error(y, predicted_home_prices)
由于模型的实际价值在于对新数据进行预测,因此我们会评估模型在未用于构建模型的数据上的性能。最直接的方法是将部分数据从模型构建过程中排除,然后用这些数据来测试模型在之前未见过的数据上的准确性。这些数据被称为验证数据,划分验证数据的时候要注意等比例划分。
scikit-learn 库有一个函数 train_test_split ,可以将数据按等比例分成两部分。我们将使用其中一部分数据作为训练数据来拟合模型,并将另一部分数据作为验证数据来计算 mean_absolute_error 。
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
# The split is based on a random number generator. Supplying a numeric value to
# the random_state argument guarantees we get the same split every time we
# run this script.
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(train_X, train_y)
# get predicted prices on validation data
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))欠拟合和过拟合(Underfitting and Overfitting)
实际上,一棵树从顶层(所有房屋)到叶子节点之间有 10 个分支的情况并不少见。随着树的深度增加,数据集会被分割成越来越多的叶子节点,每个叶子节点包含的房屋数量也会减少。如果一棵树只有 1 个分支,它会将数据分成 2 组。如果每组再被分割一次,就会得到 4 组房屋。再将每组房屋分割一次,就会得到 8 组。如果我们通过在每一层都增加分支来不断增加组数,那么到第 10 层时,我们将得到 2^10也就是1024个节点
当我们把房屋分散到许多叶子上时,每个叶子上的房屋数量也会减少。房屋数量很少的叶子做出的预测会非常接近这些房屋的实际价值,但它们对新数据的预测可能非常不可靠(因为每个预测都只基于少数房屋)。这是一种称为过拟合的现象,即模型几乎完美地拟合了训练数据,但在验证集和其他新数据上的表现却很差。
另一方面,如果我们把决策树做得非常浅,它就无法将房屋划分成非常清晰的组别。极端情况下,如果一棵树只将房屋分成 2 或 4 组,每组房屋的种类仍然非常丰富。这样一来,即使在训练数据中,大多数房屋的预测结果也可能与实际情况相差甚远(同样的原因,在验证集上也会表现不佳)。当模型无法捕捉数据中重要的差异和模式,以至于即使在训练数据上表现也很差时,这种情况称为欠拟合。
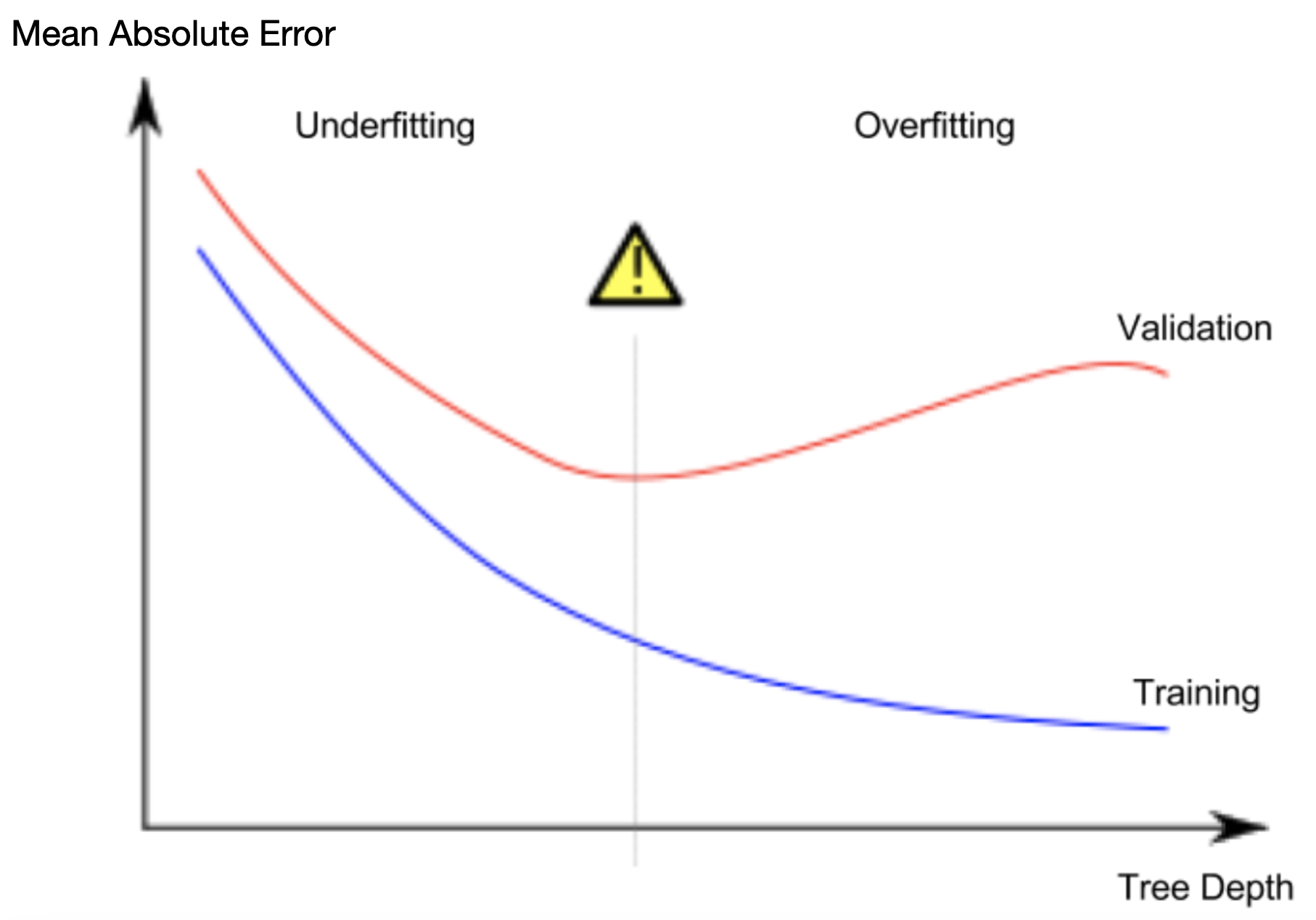
控制决策树深度的方法有很多,许多方法允许树中的某些路径比其他路径更深。但 `max_leaf_nodes` 参数提供了一种非常合理的方法来控制过拟合和欠拟合。我们允许模型生成的叶子节点越多,模型就越容易从上图中的欠拟合区域向过拟合区域移动。我们可以使用实用函数来帮助比较不同 max_leaf_nodes 值下的 MAE 得分:
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)我们可以使用 for 循环来比较使用不同 max_leaf_nodes 值构建的模型的准确性。
for max_leaf_nodes <strong>in</strong> [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %dMean Absolute Error:%d" %(max_leaf_nodes, my_mae))随机森林
随机森林使用许多决策树,并通过对每棵树的预测结果取平均值来进行预测。它通常比单个决策树具有更高的预测精度,并且在默认参数下也能很好地工作。如果持续建模,可以学习到性能更优的更多模型,但其中许多模型对参数的设置非常敏感。
我们构建随机森林模型的方式与在 scikit-learn 中构建决策树的方式类似——这次使用的是 RandomForestRegressor 类而不是 DecisionTreeRegressor 类。
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
forest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y, melb_preds))
文章评论