无论是打数模还是单纯的搞机器学习,都需要对最后训练结果进行分析,这时候常用的四个指标:准确率、召回率、精确率、F1分数。
作为指标,一定会涉及几个方面
- 用来描述什么
- 如何计算的
- 指标的意义是什么
那为了计算这几个指标,我们需要了解什么是TP、TN、FP、FN
用识别苹果举例
假设我们有100张照片:
其中有40张是真的苹果照片称之为正样本。
另外60张不是苹果照片称之为负样本。
模型预测可能有四种情况: - 预测是苹果,实际是苹果,TruePositive (TP)
- 预测是苹果,实际不是苹果,FalsePositive (FP)
- 预测不是苹果,实际是苹果,FalseNegative (FN)
- 预测不是苹果,实际也不是苹果,TrueNegative (TN)
True or False =有没有猜对
Positive or Negative 表示猜的结果 是不是正类,是苹果为正类。
假设:
TP (预测正确):30个
FN (漏检):10个
FP (误认为是):15个
TN (预测正确不是):45个
这四个指标可以形成一个混淆矩阵:
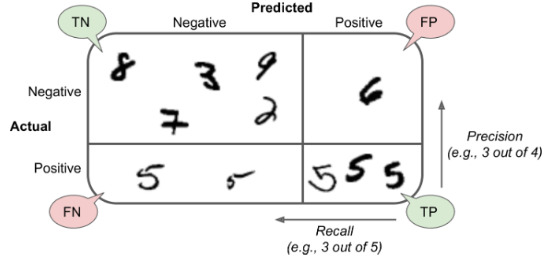
1️⃣准确率 (Accuracy)
所有预测结果中,预测正确的比例
Accuracy = \frac{{TP + TN}}{{TP + TN + FP + FN}}
最直观的指标,但在数据不平衡时表现不佳
2️⃣精确率 (Precision)
模型所有预测为“苹果”的结果中,有多少是真正的苹果
公式:{\rm{Precission = }}\frac{{{\rm{TP}}}}{{{\rm{TP + FP}}}}
是“预测的准不准”的指标,非常看重“减少误报”的场景
3️⃣召回率 (Recall)
所有真正的苹果中,被模型成功找出来了多少
公式:{\rm{Recall = }}\frac{{{\rm{TP}}}}{{{\rm{TP + FN}}}}
关注的是“找的全不全”、“减少漏检”,宁可错检也不能漏检
4️⃣F1分数 (F1-Score):精确率和召回率的调和平均数
公式:{\rm{F1 = }}\frac{{{\rm{2}} \times {\rm{(Precission}} \times {\rm{Recall)}}}}{{{\rm{Precission + Recall}}}}
F1分数综合的分数来评判模型的好坏。尤其是在数据不平衡时,比准确率更有参考价值。精确率和召回率通常是矛盾的

文章评论